Learning To Rank
1. 상대적 관계에 대한 학습
보통 Machine Learning은 대상 데이터에만 독립적인, 다른 데이터와는 관계가 없는 정보를 학습하려고 함.
ex) 통행코드 오류가 “있는가 없는가”, 이미지에 “어떤 사물이 있는가”
그런데 몇몇 경우에는 절대적 값보다는 다른 data와의 상대적 관계만 학습하면 충분한 문제들이 있음 - 추천 시스템의 경우가 대부분 해당.
이러한 문제를 해결하는 것이 바로 상대적 크기에 대한 학습, 즉 learning to rank - 절대적 값은 중요하지 않고, 그저 다른 데이터와 비교했을 때 관계만 잘 나오면 됨. - 영화 A와 B의 선호도가 각각 5, 4 일 때 5, 4를 예측하는 게 아니라 A가 B보다 더 선호된다만 예측하면 충분. 이러한 모델들은 문제 자체 뿐만아니라 문제의 정답까지 수학적으로 굉장히 잘 정의되어 있어서 딥러닝 보다는 알고리즘적 접근이 많고 굉장히 복잡한 수학적인 증명이 수반됨.
-
Ranking Model의 분류: 한 번에 몇 개의 Data를 보냐를 기준으로 나뉜다.
- Pointwise: 각 Data가 자신이 해당되는 선호도 값이 있다고 생각. 데이터의 feature을 이용해서 그 선호도를 추정하는 Regression 문제. 이 때 선호도는 다른 데이터들의 영향을 받지 않는 독립적인 값이 되므로 이는 절대적인 선호도를 추정하는 문제가 되어 딥러닝/머신러닝에서 계속 연구되어왔던 Regression 문제들과 다를 게 없어짐. 이렇게 추정한 선호도를 기준으로 Sorting 마지막에 해주는 게 전부.
- Pairwise: Data가 두 개씩 Pair로 이루어져 있고, Label은 둘 중 어떤 것이 더 선호되는지(=rank가 높은지) 만 주어짐. - 상대적인 선호도만 학습함.
- Listwise: 전체 Dataset에 대한 Ranking 또는 기준 측정값(MAP, Spearman’s rho 등등)을 optimize 하는 문제
현재 연구해야 되는 문제 때문에 이 문제를 훑어보고 있고, 이 문제에 적용하기에 Pointwise는 너무 회귀와 다를 것이 없고, Listwise를 쓰기에는 전체 set에 대한 선호 label이 정해져 있지 않아서 Pairwise를 위주로 본다.
전반적으로 Ranking Model들은 이미 만들어진 DL 모델의 output들을 다시 한 번 다른 모델로 종합시키는 Meta Model / Ensemble 성향을 띔.
2. 중요 Metric
- CG (Cumulative Gain)
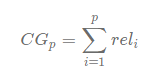
- 상위 p 개의 관련성(rel, relevance)를 합친 값
- 관련성은 기준에 따라 설정한 중요도/관심도의 척도라고 생각하면 되고, 높을수록 더 ranking이 높은 항목
-
즉, 상위 p 개에 중요도가 높은 값들이 많을 수록 좋은 추천 시스템이다
- DCG (Discounted Cumulative Gain)
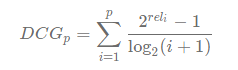
- CG을 고도화해서 중요도 높은 값을 주는 것도 중요하지만, 더 중요도 높은 값을 더 높은 순위로 추천해주는 것도 중요하다.
-
rel 값이 높은 값이 i가 낮은 값(= 높은 순위)에 있어야만 값이 극대화됨. - 중요도 제일 높은 값을 1위, 그 다음값을 2위 .. 로 선정해야만 값이 최대화
- NDCG (Normalized DCG)
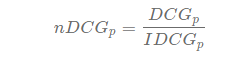
- DCG 값을 0~1로 scaling시키기 위해 만든 값.
- DCG / (DCG의 가능한 최댓값)
- DCG의 가능한 최댓값은 rel 값이 가장 높은 애가 1등, 그 다음 애가 2등 … 중요도 순위 그대로 ranking되었을 때인 optimal relevance 에서의 DCG값.
ex) 영화 1-5 의 중요도가 각각 [9, 4, 6, 2, 3], 영화 6-10은 1, top 5 추천일 때 이때 시스템1은 [영화 1, 영화 3, 영화 6, 영화 8, 영화 4] 추천 다른 시스템2는 [영화 1, 영화 2, 영화 3, 영화 5, 영화 9] 추천
시스템1 의 DCG = 2 ^ 9 / log(2) + 2^6 / log(3) + 2^1 / log(4) + 2^1 / log(5) + 2^2 / log(6) = 555.788
시스템2 의 DCG = 2 ^ 9 / log(2) + 2^4 / log(3) + 2^6 / log(4) + 2^3 / log(5) + 2^1 / log(6) = 559.088
그러면 IDCG는 중요도가 가장 높은 5개가 순서대로 추천했을 때인 [영화 1, 영화 3, 영화 2, 영화 5, 영화 4] 일 때의 DCG값이 됨
IDCG = 2^9 / log(2) + 2^6 / log(3) + 2^4 / log(4) + 2^3 / log(5) + 2^2/log(6) = 565.372
시스템1 의 nDCG = 555.788 / 565.372 = 0.983
시스템2 의 nDCG = 559.088 / 565.372 = 0.989
시스템1의 nDCG < 시스템2의 nDCG이므로 시스템2가 더 좋은 추천 시스템이라 볼 수 있다.
다양한 Pairwise Ranking Model
1. Microsoft Ranking Series
가장 먼저 이 분야에 활발하게 뛰어든 곳은 Microsoft이고, Microsoft 연구소의 Chris Burges가 총 3가지 모델로 ranking모델을 발전시킴
1) RankNet(2005)
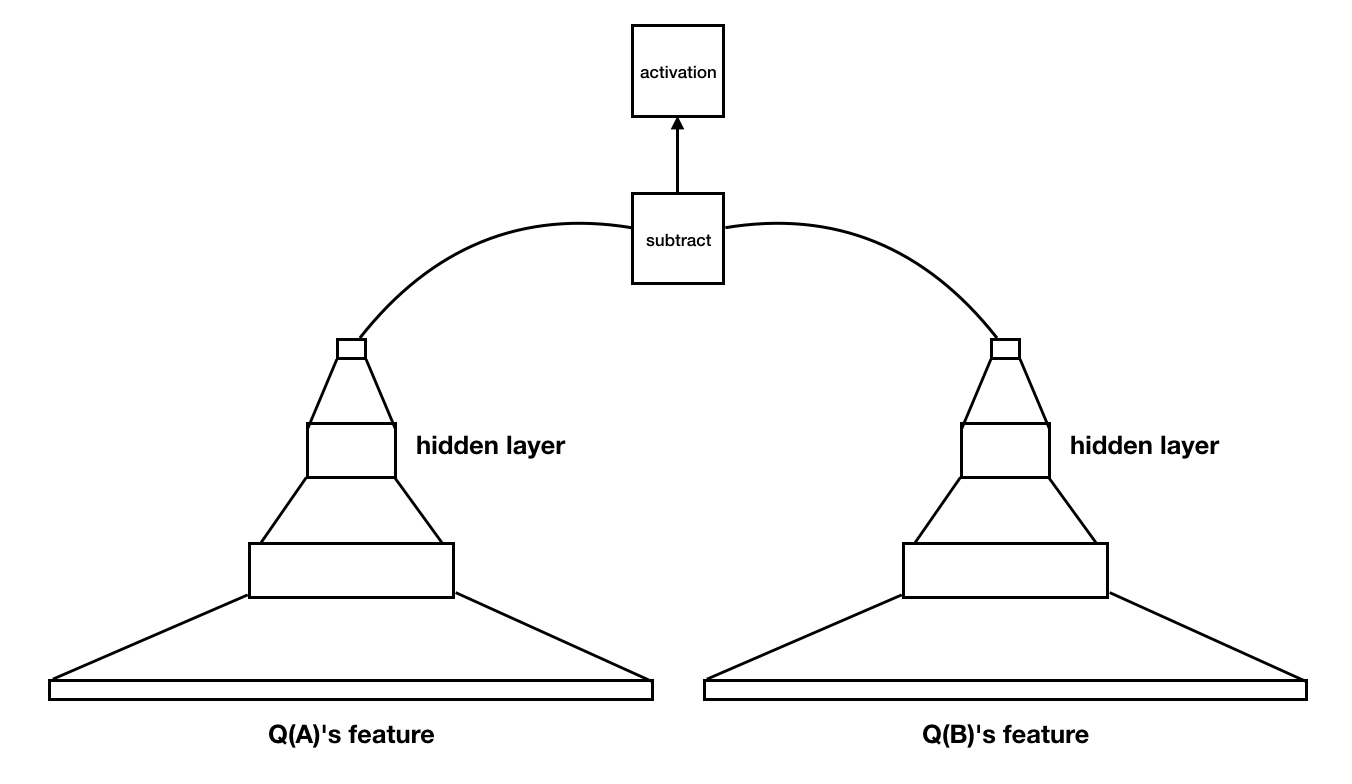
- 절대적 선호도를 측정하는 모델 한 개를 pair 안의 각 모델에 대해 적용하여 둘의 선호도를 구한 뒤, 둘 사이 차이가 상대적 선호도를 나타내도록 (A > B 이면 둘의 차의 Sigmoid 값이 1, A < B 이면 둘의 차의 Sigmoid값이 0이도록) 학습.
- 이 때 학습하는 cost는 inversion의 최소화 = A > B(= 1) 인데 0을 주는 경우, A < B(=0) 인데 1을 주는 경우. - 이러한 cost function은 아래처럼 나타나진다:
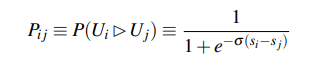
- 이는 현재 이진 분류에서 가장 많이 사용하는 loss 함수인 Binary Crossentropy와 일치함.
2) LambdaRank(2006)
- RankNet의 cost function은 pair 사이 선호의 error만을 기준으로 학습을 함 - 1등 vs 4등, 1등 vs 2등이어도 두 개의 Pair의 선호 관계는 똑같이 > 이므로 이를 똑같이 취급.
- 이 정도로도 충분한 문제라면 상관 없지만, 더 고도화된 ranking metric이 필요할 땐 적절하지 않음 - 1등 과 2등, 1등과 4등 사이 cost에 차별을 두고 싶다면?
- RankNet을 개발하면서 마이크로소프트 연구진이 깨달은 건 Cost Function 자체를 알 필요는 없고, 그 미분값 = Gradient Descent 값만 알면 된다.
- 아래 그림처럼 처음 ranking을 정하고 나선 변해야 하는 값 만큼씩 gradient descent를 해나가면 최적값에 도달한다.
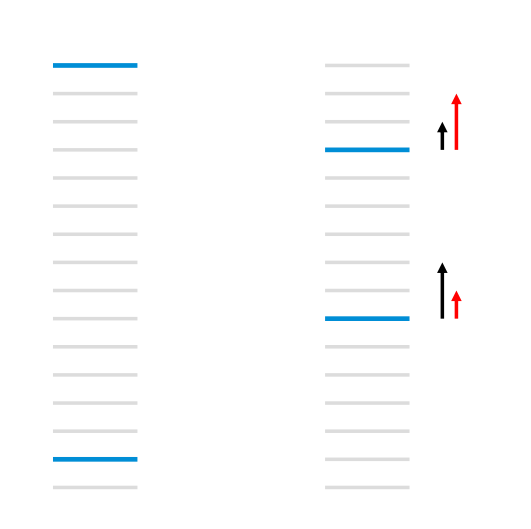
- 이를 활용해 Cost Function의 Gradient 값을 Binary Cross Entropy가 아닌 NDCG에 비례하도록 설정함으로써 더 고도화된 ranking문제를 해결할 수 있게 함.
- NDCG가 아닌 다른 metric을 사용하고 싶으면 그 값을 nDCG 대신 넣으면 되므로 확장성도 좋은 모델.
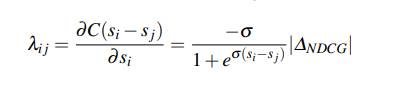
3) LambdaMART(2008)
MART(Multiple Additive Regression Tree)
- Random Forest처럼 Ensemble 모델로, Regression Tree들의 Output을 Dense하여 최종 결과를 내는 방식
Random Forest 와 MART의 차이
-
Random Tree 예제 다이어그램:
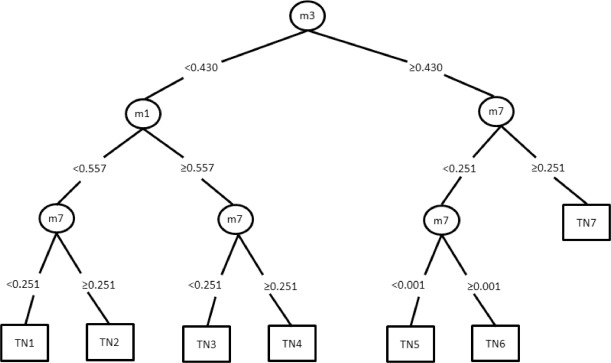
- 같은 문제를 푸는 Random Tree들 여러개 만든다. 이때, 각 Tree에서 사용할 수 있는 feature은 전체 feature의 부분집합으로 random하게 정해짐.
-
이렇게 회귀하고자 하는 함수가 f 라면 각 Tree는 이 f 를 자신이 가진 feature들로 최대한 정확하게 예측 - tree i 가 회귀한 함수가 f_i 라고 하면 f_1 - f_n 을 aggregate하여 f를 최종적으로 추정하는 방식
- MART 가 기존 앙상블과 다른 점은 랜덤 포레스트는 모든 트리가 f를 추정함에 반해 MART는 f를 추정할 때 첫 tree가 g를 추정했다면, 다음 tree는 h = f - g 를 추정하고, 다음 tree는 i = f - g - h 를 추정하는 식으로 새로운 tree가 residual을 학습하는 방식
- 이를 활용하여 각 Regression Tree가 ranking값이 아닌 loss gradient를 예측하게 만듬
- 이 예측한 Loss gradient값 만큼 순위 계속해서 조정.
다른 Pairwise Algorithm들
4) RankBoost(2003)
- Ranking 문제를 해결하기 위한 Algorithmic 방식
- Feature들 사이 Ranking을 종합하는 방법을 학습하여 최종 ranking을 만드는 방법
- ex) 영화 추천 - 별점 정도, 배우 캐스팅 수, 감독의 평점 등의 feature이 모두 랭킹화 될 수 있고, 이들을 종합하여 최종 랭킹 생성
- 최종 결과값만이 아니라 Feature들 사이에서도 ranking이 존재해야 해서 적용하기엔 제약이 많음.

5) SortNet (2008)
- Deep Learning을 이용하는 Pairwise Ranking Algorithm으로, 학습하는 ranking함수를 비교 함수로 구체화하여 문제를 해석
- 결국 ranking 문제는 A 가 B보다 선호 되면 양수, 덜 선호되면 음수, 같으면 0을 주는 함수를 학습하는 걸로 생각할 수 있고, 이는 곧 비교 함수이다.
- 즉, 비교 함수를 학습하는 방식으로 Deep Learning Network 를 구성하면 효과적인 결과를 얻을 수 있다.
비교 함수의 특성
ranking 비교 함수는 위에서 말한 크기 대소 뿐만 아니라 다음과 같은 함수 특성을 지녀야 한다:

- Reflexivity/Equivalence: 선호 입장에서 당연함
- Antisymmetry: A가 B 이상 선호되고, B도 A 이상 선호되면 당연히 둘은 같은 선호도다.
- Transitivity: A가 B 경로보다 선호되고, B 경로가 C 경로보다 선호되면 A 경로는 C보다도 선호되어야 한다.
이러한 특성들을 모델에 갖추기 위해서 모델을 > 과 < 값을 계산하는 두 개의 모델 N_<, N_>로 나눴고, 둘은 같은 weight을 공유한다
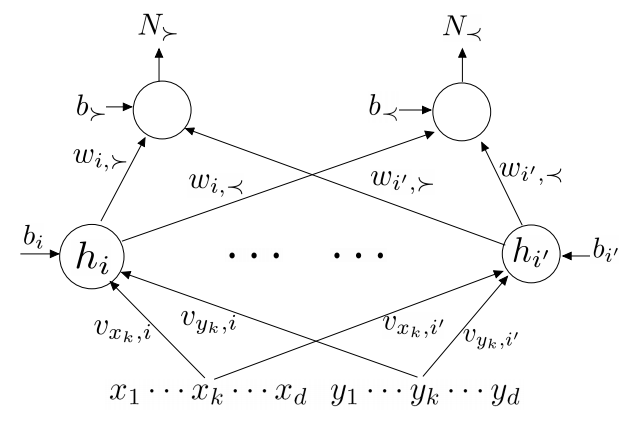
-
Symmetric한 특성을 맞추기 위해 모델 diagram의 대칭적인 weight들은 서로 값이 같음
-
대칭성을 보여주기 위해 diagram을 엄청 복잡하게 만들었지만, 결국 이 diagram은 아래처럼 같은 model을 input만 바꿔서 두 번 통과 시킨 것과 같다:
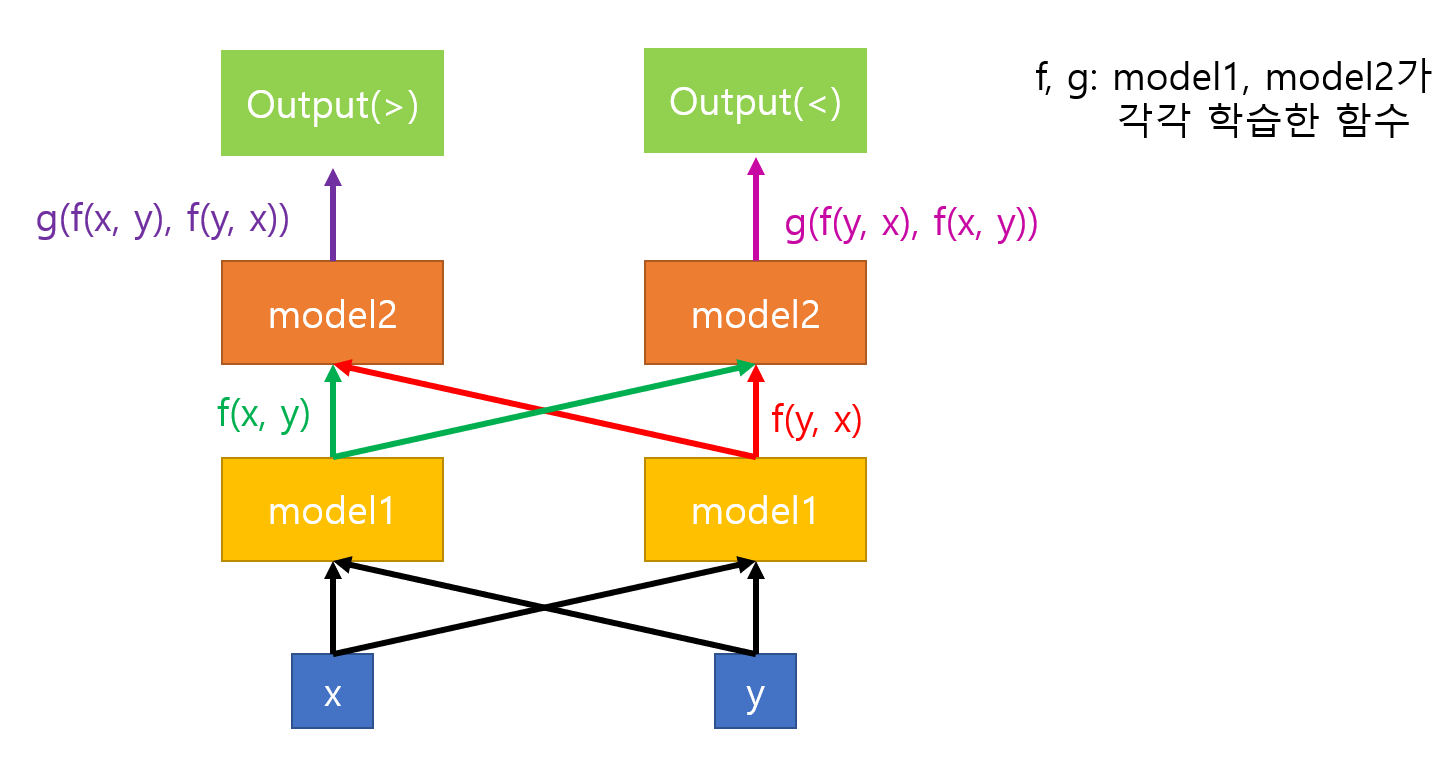
6) FaceNet
- 얼굴 인식에서도 Pairwise Data 식별이 중요한 데, 보안 문제에서 두 image가 같은 사람의 얼굴인지를 판별하는 것이 Face Recognition보안의 핵심이다.

- FaceNet 문제의 특수성은 데이터 사이 관계가 선호라는 일차원 관계로만 정의되는게 아니라 Positive한 관계 (두 사진이 같은 사람)와 Negative한 관계(두 사람은 다른 사람) 이 같이 있는 이차원 관계로 정의됨
- 이 모델의 목적은 Negative한 관계는 Embedding state사이 거리가 멀어지고, Positive한 관계는 거리가 가까워지도록 학습하는 것.
- 현재 연구중인 문제는 이렇게 양/음 관계가 같이 정의되진 않아서 아이디어만 확인하고 넘어감.
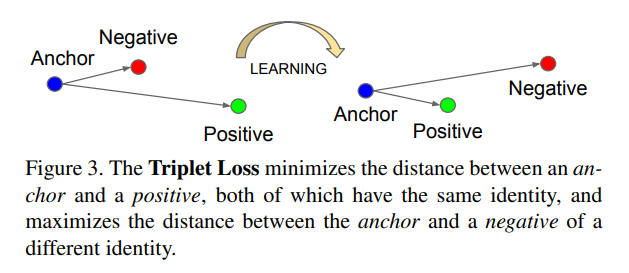
7) DirectRanker
- RankNet의 일반화 버전
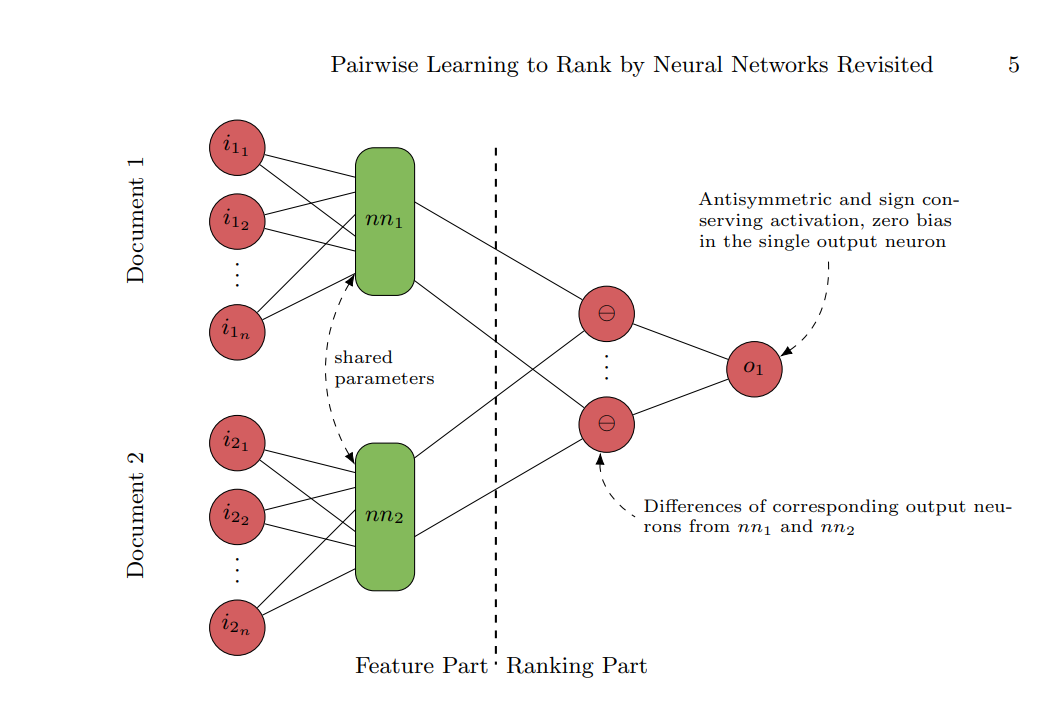
- 위 형태의 구조는 정답셋이 open, convex같은 특정 조건을 만족하면 최적의 값으로 회귀할 수 있음을 수학적으로 증명.
- RankNet뿐만 아니라 Model이 구현하는 비교 함수가 Reflexivity, Antisymmetricity, Reflexity를 만족해야 하는 것, 그리고 같은 Model을 사용해서 x, y 각각의 Feature Output을 구하는 것 등 많은 방면에서 SortNet과 비슷
- 그 다음 output layer는 둘 사이의 차로 이루어져 있고, 이들을 다시 종합해 antisymmetric activation function(ex) y=x, y=tanh(x)) 를 통과시켜 마지막 결과 얻음.
- y = tanh(x/2) 활성화 함수와 cost로 binary crossentropy를 사용하면 RankNet이 됨 - 활성화 함수, cost function, Model에 대한 일반화
- 이 또한 마찬가지로 전체 Dataset에 대한 선호 대소가 정의되어있어야함.